
Temps de lecture : 15 min
Points clés à retenir
- Une réduction de 70 % des coûts de stockage des logs d'IA grâce au format colonnaire Apache Parquet.
- Une architecture hybride associant Apache Calcite, Apache DataFusion et Lucene pour séparer recherche et analytique.
- L'incompatibilité avec le langage Query DSL traditionnel d'OpenSearch, imposant l'usage de SQL ou de PPL.
- L'obligation opérationnelle de créer un nouveau domaine OpenSearch dédié pour déployer cette technologie.
Avec une augmentation de 93 % du volume de logs générés par les charges de travail d’intelligence artificielle en un an, les entreprises se retrouvent aujourd’hui face à une crise budgétaire de stockage sans précédent. L’analyse de la télémétrie applications IA sature les infrastructures traditionnelles de supervision. Pour maîtriser leurs budgets d’observabilité, 86 % des organisations sacrifient désormais leurs données de logs en les excluant délibérément de leurs analyses. Face à ce défi majeur, le nouveau moteur d’analyse des logs AWS intégré au sein d’Amazon OpenSearch Service promet une réduction de 70 % des coûts de stockage, au prix d’une migration technique particulièrement contraignante.
L’explosion de la télémétrie IA : Pourquoi les architectures traditionnelles saturent
Le comportement bavard des agents d’intelligence artificielle générative
Pourquoi les agents d’intelligence artificielle génèrent-ils autant de logs ? La réponse réside dans la nature même de leur exécution et de leur logique interne. Contrairement à une application classique qui effectue un appel de base de données linéaire, un agent autonome formule des hypothèses, effectue des boucles de réflexion successives et consulte des bases documentaires via du RAG (Retrieval-Augmented Generation). Chaque étape de ce processus génère une quantité massive de traces de débogage et d’appels API en arrière-plan.
En pratique, le suivi opérationnel de la télémétrie applications IA devient ainsi un gouffre financier insurmontable pour les équipes DevOps. Les interactions constantes entre les modèles, les bases de connaissances et les orchestrateurs multiplient par dix, voire par cent, le volume de données à stocker. Si chaque appel de modèle génère plusieurs kilo-octets de traces de raisonnement et de contextes d’invite, les bases d’indexation traditionnelles s’effondrent rapidement sous le poids des gigaoctets accumulés toutes les minutes.
Définition de la télémétrie IA : La télémétrie des applications d’intelligence artificielle englobe l’ensemble des données de diagnostic, de traces d’exécution et de logs de requêtes générées par les modèles d’apprentissage et les agents autonomes. Ce phénomène se caractérise par des agents logiciels qui interrogent continuellement les systèmes d’information en arrière-plan, effectuant des appels API répétés, des passes de raisonnement multi-étapes et des accès constants aux bases de connaissances (RAG), ce qui engendre une surcharge d’événements et une multiplication exponentielle des volumes de données à traiter.
Le dilemme de la conservation : Sécurité versus coûts d’infrastructure
Pourquoi les coûts d’observabilité augmentent-ils avec l’intelligence artificielle ? Tout simplement parce que stocker, indexer et maintenir interrogeables ces millions de micro-décisions sature les bases de données traditionnelles. En 2025, une enquête de l’éditeur Dynatrace révélait une statistique alarmante : le volume des logs liés aux charges de travail d’intelligence artificielle a augmenté de 93 % par rapport à l’année précédente. Pour les directeurs financiers et techniques, cette inflation de données est devenue insoutenable.
Cette explosion se heurte à la réalité économique des budgets cloud. Selon cette même enquête de Dynatrace en 2025, les organisations excluent en moyenne 86 % de leurs données de logs pour maîtriser les coûts et la capacité système. On parle ici d’une hausse potentielle de 93 % de leur budget global d’observabilité si elles décidaient de tout conserver. En pratique, cette cécité volontaire pose un risque majeur pour la sécurité informatique, la conformité et la traçabilité des décisions prises par les modèles. Les équipes techniques doivent arbitrer entre la ruine budgétaire et l’absence totale de visibilité sur les erreurs de production.
Afin de stopper cette dérive financière sans couper le sifflet aux outils de monitoring de la télémétrie applications IA, AWS a repensé les fondations de son système de stockage, en introduisant un mécanisme hybride innovant.
Le nouveau moteur d’analyse des logs AWS OpenSearch : Comment ça marche ?
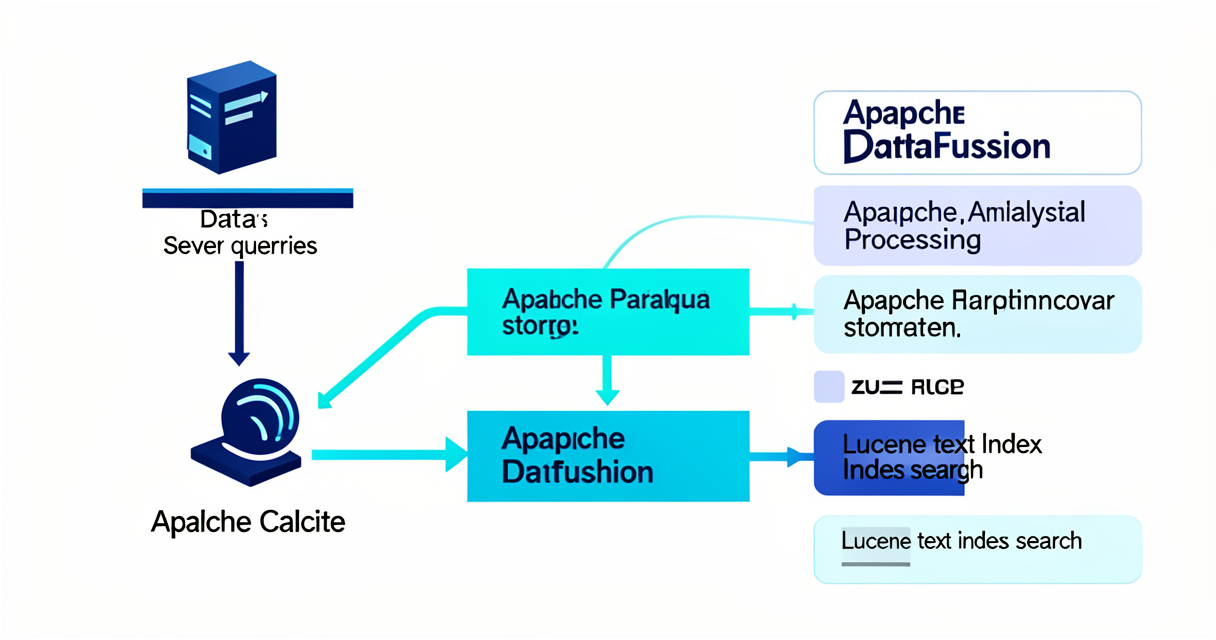
Le nouveau moteur d’analyse des logs d’AWS OpenSearch fonctionne en combinant le stockage en colonnes Apache Parquet avec les index Lucene pour les champs consultables. Il utilise Apache Calcite pour analyser et optimiser les requêtes, puis distribue l’analytique vers Apache DataFusion et la recherche textuelle vers Lucene au sein d’une seule et même requête.
Comment fonctionne le moteur de logs OpenSearch optimisé pour l’intelligence artificielle ? Ce système découple le traitement des données pour contourner les goulots d’étranglement de l’indexation totale. Au lieu d’indexer chaque octet de texte dans des structures lourdes, le moteur d’analyse des logs AWS sépare la recherche textuelle de l’agrégation analytique brute.
Ce qui fait vraiment la différence, c’est la manière dont le stockage et l’indexation travaillent main dans la main. AWS conserve les données de télémétrie brutes sous forme compressée et colonnaire, tout en maintenant un index inversé très léger pour les seuls champs indispensables aux filtres d’analyse, comme les identifiants de requêtes ou les codes d’erreur.
L’articulation entre stockage en colonnes et indexation Lucene
Pour comprendre cette mécanique, il faut regarder sous le capot d’Amazon OpenSearch Service. Traditionnellement, Lucene gère l’ensemble des requêtes en parcourant des index inversés complexes. Cette approche excelle pour la recherche plein texte, mais s’avère extrêmement gourmande en ressources processeur et mémoire lorsque l’on souhaite réaliser des calculs de moyenne ou des regroupements sur des milliards de lignes.
Désormais, le moteur d’analyse des logs AWS n’indexe plus systématiquement l’intégralité des attributs de vos journaux. Les champs à faible cardinalité ou destinés aux calculs statistiques sont stockés sous forme de colonnes optimisées. Cette dualité permet d’accélérer les requêtes d’agrégation tout en conservant une capacité de filtrage textuel ultra-ciblée. Soyons clairs : c’est une rupture majeure avec le modèle monolithique historique d’Elasticsearch.
Le trio technologique : Apache Calcite, Apache DataFusion et Lucene
Quels sont les composants du moteur de logs AWS ? Ce système repose sur l’intégration harmonieuse de trois technologies open-source majeures. En amont, Apache Calcite intervient pour interpréter les requêtes envoyées par l’utilisateur, dresser un plan d’exécution optimisé et séparer les opérations logiques.
Une fois le plan de requête établi, la charge de travail est distribuée. D’un côté, Apache DataFusion prend en charge l’exécution des calculs analytiques vectorisés directement sur le stockage en colonnes. De l’autre, Lucene résout les filtres textuels complexes. Cette répartition des tâches garantit des performances inégalées sur des volumes de données massifs au sein d’Amazon OpenSearch Service.
| Composant Interne | Rôle Principal dans le Moteur | Bénéfice Clé pour les Logs d’IA |
|---|---|---|
| Apache Calcite | Analyse syntaxique, planification et optimisation logique des requêtes SQL/PPL. | Garantit que chaque requête est découpée et adressée au moteur le plus performant. |
| Apache DataFusion | Exécution ultra-rapide des agrégations analytiques sur données colonnaires. | Permet de calculer des statistiques sur des milliards d’événements sans surcharge mémoire. |
| Lucene | Recherche textuelle plein texte et filtrage par index inversé traditionnel. | Conserve une recherche rapide de mots-clés spécifiques dans les messages d’erreur. |
Ce découpage de l’architecture logicielle a des répercussions directes et massives sur la facture d’infrastructure cloud des entreprises.
Les gains réels : Réduction de 70 % des coûts de stockage sous Apache Parquet
Quelle est l’économie réelle offerte par Apache Parquet dans OpenSearch ? L’utilisation combinée du format Apache Parquet OpenSearch permet de diviser par trois l’espace disque nécessaire. Selon les mesures officielles publiées par AWS en 2026, le nouveau moteur optimisé d’OpenSearch permet de réduire les coûts de stockage de 70 %. Pour une entreprise gérant plusieurs téraoctets de données quotidiennes, l’impact financier est immédiat.
Comment OpenSearch réduit-il la facture de stockage de ses journaux ? Les architectures de recherche traditionnelles s’appuient sur des index Lucene volumineux, qui doublent souvent la taille physique des fichiers plats originaux. En remplaçant ces index par des fichiers Parquet compressés avec des algorithmes modernes comme ZSTD, le système élimine la redondance inhérente aux structures de données temporelles. Cette réduction coûts stockage OpenSearch permet d’alléger considérablement l’infrastructure de stockage.
Les avantages du format colonnaire Apache Parquet pour les séries temporelles
Le stockage en colonnes structure les données par attribut plutôt que par ligne. Pour des logs d’IA constitués de champs répétitifs (noms de modèles, timestamps, identifiants d’API), ce format offre des taux de compression exceptionnels. En pratique, le moteur ne lit que les colonnes nécessaires à la requête en cours, évitant ainsi d’analyser l’intégralité du disque.
Cette intégration de la technologie Apache Parquet OpenSearch transforme la gestion du cycle de vie des données. Les informations de télémétrie, autrefois stockées sur des disques SSD coûteux pour rester interrogeables, peuvent désormais transiter sur des solutions de stockage objet beaucoup plus abordables comme Amazon S3, tout en restant accessibles pour des analyses directes.
Conserver plus longtemps : L’impact positif sur la conformité et la sécurité
Cette réduction coûts stockage OpenSearch lève un verrou technique majeur. Auparavant, conserver les journaux d’activité des agents autonomes pendant plus de quelques semaines s’avérait financièrement intenable pour la plupart des structures. Désormais, le coût marginal de stockage d’un mois supplémentaire devient négligeable, permettant d’aligner la politique de conservation sur les exigences réglementaires et de sécurité les plus strictes.
Je me souviens d’une discussion avec le directeur informatique d’une grande banque européenne en 2025. Pour éviter l’explosion de sa facture cloud liée aux logs d’un nouvel agent conversationnel client, il avait été contraint d’échantillonner ses logs de sécurité, n’en conservant qu’un sur dix. Ce compromis historique, bien que risqué en matière d’audit, était la seule solution budgétaire viable. La mise en place de la réduction coûts stockage OpenSearch a radicalement changé la donne pour son équipe. En migrant vers le format Apache Parquet OpenSearch, il a pu réintégrer la totalité de ses flux de télémétrie tout en réduisant ses dépenses d’infrastructure.
Cependant, cette baisse spectaculaire des tarifs s’accompagne de contreparties techniques substantielles qu’il faut évaluer avec lucidité.
Les limites techniques et l’absence du DSL OpenSearch
L’incompatibilité avec le langage DSL traditionnel d’OpenSearch
Quels sont les inconvénients du nouveau moteur de logs OpenSearch ? Le principal point de friction réside dans l’abandon de pans entiers de l’écosystème OpenSearch standard. Pour obtenir ces gains d’espace et de performance, AWS a dû faire des choix architecturaux drastiques qui limitent la flexibilité historique du moteur.
Le premier compromis concerne la perte de la recherche plein texte arbitraire sur l’ensemble des champs. Les requêtes complexes nécessitant des jointures ou des filtres sur des colonnes non indexées subissent une baisse de performance notable. Soyons clairs : ce moteur est un outil spécialisé pour l’analytique de masse, pas un substitut universel pour toutes vos applications de recherche.
Pourquoi le langage DSL n’est-il pas supporté dans le moteur optimisé d’AWS ? La raison est structurelle. Le langage Query DSL (Domain Specific Language) hérité d’Elasticsearch est intrinsèquement lié à l’indexation totale de Lucene. Ce langage suppose que chaque champ dispose d’un index inversé prêt à être interrogé.
Le stockage colonnaire en fichiers Parquet ne peut pas interpréter nativement le formalisme JSON du Query DSL. Pour interroger ces données compressées, le système doit passer par un moteur de requêtes SQL ou PPL. Cette rupture technologique représente l’une des principales limites du moteur de logs OpenSearch AWS, car elle invalide des années de scripts et d’habitudes de requêtage chez les ingénieurs système.
L’impact sur vos tableaux de bord et vos alertes existants
En pratique, cela signifie que vos consoles d’observabilité, comme OpenSearch Dashboards ou Grafana, ne fonctionneront pas de manière transparente avec ce nouveau moteur si elles s’appuient sur des requêtes DSL classiques. Vos visualisations et vos graphiques de tendance devront être intégralement retravaillés.
Les limites du moteur de logs OpenSearch AWS touchent également vos mécanismes de surveillance active. Si vous avez configuré des détecteurs d’anomalies ou des systèmes d’alerte automatique basés sur le DSL, ces règles devront être réécrites sous peine de devenir totalement inopérantes après le déploiement.
Avertissement critique pour la production : N’envisagez pas de basculer vers cette architecture sans avoir préalablement audité et planifié la réécriture complète de vos règles d’alerte et de vos tableaux de bord opérationnels. L’absence de support du langage DSL historique d’Elasticsearch/OpenSearch signifie que tout votre outillage de monitoring actuel basé sur des requêtes JSON brutes cessera de fonctionner immédiatement après la bascule.
Cette transition vers un nouveau paradigme de requêtage impose une stratégie de migration rigoureuse, excluant toute approche automatisée simple.
Guide de migration : Comment passer au nouveau moteur d’analyse des logs ?
L’obligation de créer un nouveau domaine OpenSearch dédié
Peut-on activer le moteur de logs sur un domaine OpenSearch existant ? La réponse est catégorique : c’est impossible. Ce moteur n’est pas une simple option que l’on coche dans les paramètres ou un plugin que l’on installe sur un cluster en production. Son intégration nécessite une refonte fondamentale du stockage au niveau du système de fichiers.
Par conséquent, vous devez planifier une véritable migration domaine OpenSearch de bout en bout. Les index existants ne peuvent pas être convertis à la volée vers le format colonnaire optimisé. Il faut donc concevoir et déployer une infrastructure parallèle pour accueillir vos nouveaux flux de télémétrie.
La première étape consiste à configurer un tout nouveau domaine d’analyse au sein de la console AWS. C’est lors de cette phase de provisionnement initial que vous spécifierez l’utilisation du moteur optimisé pour les logs. Ce domaine fonctionnera avec sa propre tarification et ses propres règles d’allocation de ressources.
Cette contrainte complique la phase transitoire de la migration domaine OpenSearch. Pendant plusieurs semaines, vous devrez probablement faire cohabiter l’ancien et le nouveau domaine. Cette période d’exécution en parallèle est indispensable pour s’assurer de la stabilité du nouveau système avant de couper définitivement les anciennes bases de données.
Exploiter la compatibilité de l’API Bulk pour simplifier l’ingestion
Comment migrer ses pipelines d’ingestion vers le nouveau moteur AWS ? Heureusement, AWS a maintenu la compatibilité avec l’API Bulk au niveau de la couche d’ingestion. Vos agents de collecte de logs (comme FluentBit, Logstash ou OpenTelemetry Collector) n’ont pas besoin d’être modifiés en profondeur.
Il vous suffit de modifier l’adresse de destination (l’endpoint) dans les fichiers de configuration de vos collecteurs pour rediriger les flux de votre migration domaine OpenSearch vers le nouveau domaine OpenSearch. L’API Bulk accepte les payloads structurés de la même manière, ce qui évite d’avoir à réécrire le code applicatif qui génère les événements.
- Étape 1 : Provisionner le nouveau domaine : Créez une instance OpenSearch dédiée en activant spécifiquement le moteur d’analyse des logs optimisé depuis votre console d’administration AWS.
- Étape 2 : Dupliquer et rediriger les flux d’ingestion : Mettez à jour les configurations de vos agents de télémétrie (Logstash, FluentBit) pour adresser les données au nouveau domaine via l’API Bulk compatible.
- Étape 3 : Recréer l’outillage analytique en SQL/PPL : Traduisez vos requêtes de surveillance, vos graphiques OpenSearch Dashboards et vos règles d’alertes en abandonnant le DSL traditionnel.
- Étape 4 : Phase de double run et extinction : Validez la cohérence des données sur le nouveau domaine durant une période d’observation, puis éteignez progressivement l’ancien cluster généraliste devenu obsolète.
Une fois le pipeline de données réacheminé, l’effort principal se concentre sur l’apprentissage et l’implémentation des nouveaux langages de requêtage.
SQL et PPL : Remplacer le langage de requête DSL pour l’analytique
Introduction au Piped Processing Language (PPL) pour l’analyse opérationnelle
Qu’est-ce que le langage PPL et comment remplace-t-il le DSL d’OpenSearch ? Le Piped Processing Language (PPL) propose une syntaxe séquentielle inspirée des commandes Unix ou du langage SPL de Splunk. Contrairement au DSL qui nécessite des structures JSON imbriquées et complexes, le langage PPL OpenSearch permet de chaîner les opérations de filtrage, de tri et d’agrégation à l’aide du caractère pipe (|).
Cette approche linéaire rend l’analyse de données beaucoup plus intuitive pour les ingénieurs système. En pratique, une requête PPL commence par la sélection de la source de données, suivie de filtres successifs, pour finir par une fonction d’agrégation. Le langage PPL OpenSearch devient ainsi le couteau suisse des investigations rapides sur incident.
La force du PPL réside dans sa lisibilité. Pour rechercher des codes d’erreur spécifiques dans des millions de lignes de logs d’IA, une simple ligne de commande PPL remplace des dizaines de lignes de JSON. Les opérateurs de filtrage classiques comme ‘where’, ‘search’ et ‘stats’ permettent de structurer la donnée à la volée.
Pour les équipes habituées au requêtage Elasticsearch classique, la courbe d’apprentissage est rapide. Ce langage résout le problème de la complexité syntaxique du DSL tout en offrant des performances optimales sur le stockage colonnaire Apache Parquet, grâce aux optimisations de bas niveau réalisées par Apache Calcite.
Exemples de requêtes SQL hybrides combinant analytique et recherche Lucene
Comment utiliser SQL dans le nouveau moteur de logs OpenSearch ? Le moteur expose un endpoint SQL standard. Vous pouvez soumettre des requêtes relationnelles classiques pour interroger vos fichiers de logs. C’est une excellente nouvelle pour les analystes métiers qui maîtrisent déjà ce langage universel.
L’intérêt majeur réside dans la capacité du moteur à combiner la puissance analytique du SQL avec les performances de recherche textuelle de Lucene. Vous pouvez par exemple utiliser des fonctions de recherche plein texte à l’intérieur d’une clause WHERE dans une requête SQL classique d’agrégation. Cette hybridité permet d’obtenir le meilleur des deux mondes sans compromis.
| Langage de requête | Style de syntaxe | Exemple de requête (Recherche d’erreurs 500) |
|---|---|---|
| Query DSL traditionnel | JSON verbeux imbriqué | { "query": { "match": { "status": 500 } } } |
| SQL natif | Déclaratif relationnel | SELECT * FROM logs WHERE status = 500; |
| Piped Processing Language (PPL) | Séquentiel avec pipes (|) | source=logs | where status=500; |
Adopter ces nouvelles syntaxes comme le langage PPL OpenSearch demande un investissement initial en formation, mais s’avère payant face aux enjeux économiques de l’ère de l’intelligence artificielle.
L’optimisation de l’analyse des logs d’intelligence artificielle dans OpenSearch par AWS s’impose comme une réponse forte face aux coûts exponentiels de l’observabilité. En combinant le format de stockage Apache Parquet avec une architecture logicielle moderne reposant sur Apache Calcite et Apache DataFusion, le giant du cloud propose une baisse promise de 70 % des coûts de stockage pour vos environnements de production.
Néanmoins, cette transition exige des arbitrages techniques majeurs de la part des équipes DevOps. L’obligation de créer un nouveau domaine OpenSearch et l’absence totale de support pour le langage de requête DSL historique obligent à une refonte complète des règles d’alertes et des dashboards. Ce qui fait vraiment la différence sera la capacité des organisations à former leurs ingénieurs aux syntaxes SQL et PPL.
Alors que l’optimisation financière de la télémétrie devient vitale pour le déploiement des agents autonomes à grande échelle, votre équipe technique est-elle prête à abandonner le DSL historique pour sauver son budget cloud ?
Questions fréquentes
Pourquoi les applications d'intelligence artificielle génèrent-elles autant de logs ?
Les agents IA effectuent de nombreuses requêtes et appels API en arrière-plan pour raisonner ou accéder aux bases de connaissances (RAG). Ces interactions constantes multiplient le volume de données de télémétrie par rapport aux applications traditionnelles.
Quels sont les avantages du format en colonnes Apache Parquet dans OpenSearch ?
Apache Parquet compresse fortement les données répétitives comme les logs, réduisant l'espace de stockage de 70 %. De plus, son format colonnaire accélère considérablement les requêtes d'agrégation analytique sans surcharger les index.
Peut-on activer le nouveau moteur de logs sur un domaine OpenSearch existant ?
Non, il est impossible d'ajouter ce moteur à un domaine existant ou de l'activer sur des index individuels. Son adoption requiert la création d'un nouveau domaine OpenSearch dédié et la migration des flux d'ingestion.
Comment contourner l'absence de support du langage DSL d'OpenSearch ?
Vous devez réécrire vos requêtes, alertes et tableaux de bord en utilisant SQL ou le langage Piped Processing Language (PPL). L'API Bulk reste cependant compatible pour l'ingestion sans modification du code applicatif.

Expert SaaS & Productivité
Expert en outils digitaux et productivité depuis plus de 12 ans, ancien chef de produit dans l’univers SaaS, j’analyse et teste des dizaines de solutions chaque année.
Mon approche ? Une analyse comparative rigoureuse avec transparence totale sur les forces ET les limites de chaque outil.
Objectif : vous aider à faire les bons choix technologiques pour votre activité.
Expertises : Analyse SaaS • Outils de productivité • CRM & Marketing automation • Comparatifs produits • Tests terrain